Hash Table
Created: 2022-07-04
Tags: #fleeting
Abstract:
The idea of hash table is to provide constant time for every search.
Conceptually
a hash table is an array, with a hash function
There are many different types of hash functions
But this is what you need to keep in mind
A hash function
Calling a hash function for some input
-
should always produce the same output
-
needs to be fast.
-
We want different inputs to produce different outputs
-
If not followed then our hash table isn't gonna work
-
If hash function takes a long time, then that's no good
Hash table allows you to add more values in a single bucket. This is also called a collision. We can use a linked list to store more values in a single bucket. We could also do linear probing.
Two ways people handle collision in Hash Table
Open Addressing
- keep everything in the table. If the bucket is full, we're gonna find anohter bucket. Can be done either by using the hash function again, but we can also do linear probing.
Table is always gonna be the same size
Once its full, then its full. Be a good thing or a bad thing depending on how your program works.
Unforunately, once your table fills up
All claims about - hash tables being fast
Those claims will disappear
Alternative to Open Addressing
External Chain
Your always gonna put the objects into the table location that was chosen by the hash function
We don't look for an empty space, we just simply assign a memory by linked list and chain them up. Basically what the CS50 showed
We can represent the letters of the Alphabet here.
0 for A till to 25 for Z.

There's an array vertically here. The extra names can be used as "linked lists". -
The array has 26 pointers, some of which are null, but some pointing to a name in a node, each of which may also point to another name in another node.
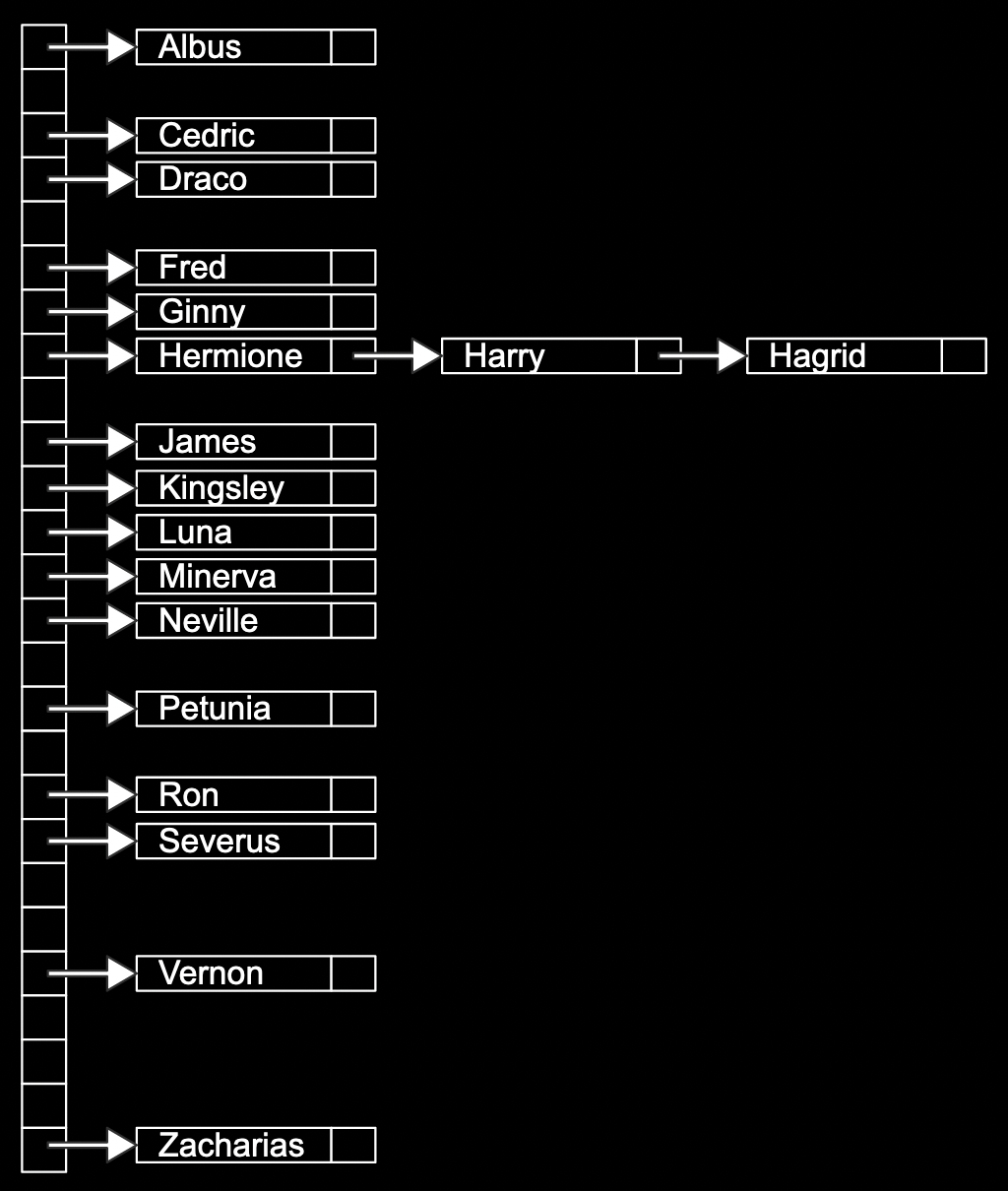
Hash Table is technically faster than a single linked_list.
But it's only gonna be fast when there aren't that many nodes in a single bucket.
Also it takes much more useless space as some pointers have null value into them.
Creating a hash table
typedef struct node
{
char word[LONGEST_WORD + 1];
struct node *next;
}
node;
To create a hash_table thing. NUMBER_OF_BUCKETS is the size of the hash table.
node *hash_table[NUMBER_OF_BUCKETS];
Decide which bucket/location in the array,
that a value should be placed in,
we use a hash function, which takes some input and produces an index, or location.
typedef struct item
{
char* key;
int value;
}
item;